
Our 2026 Mid-market Analytics Maturity Survey
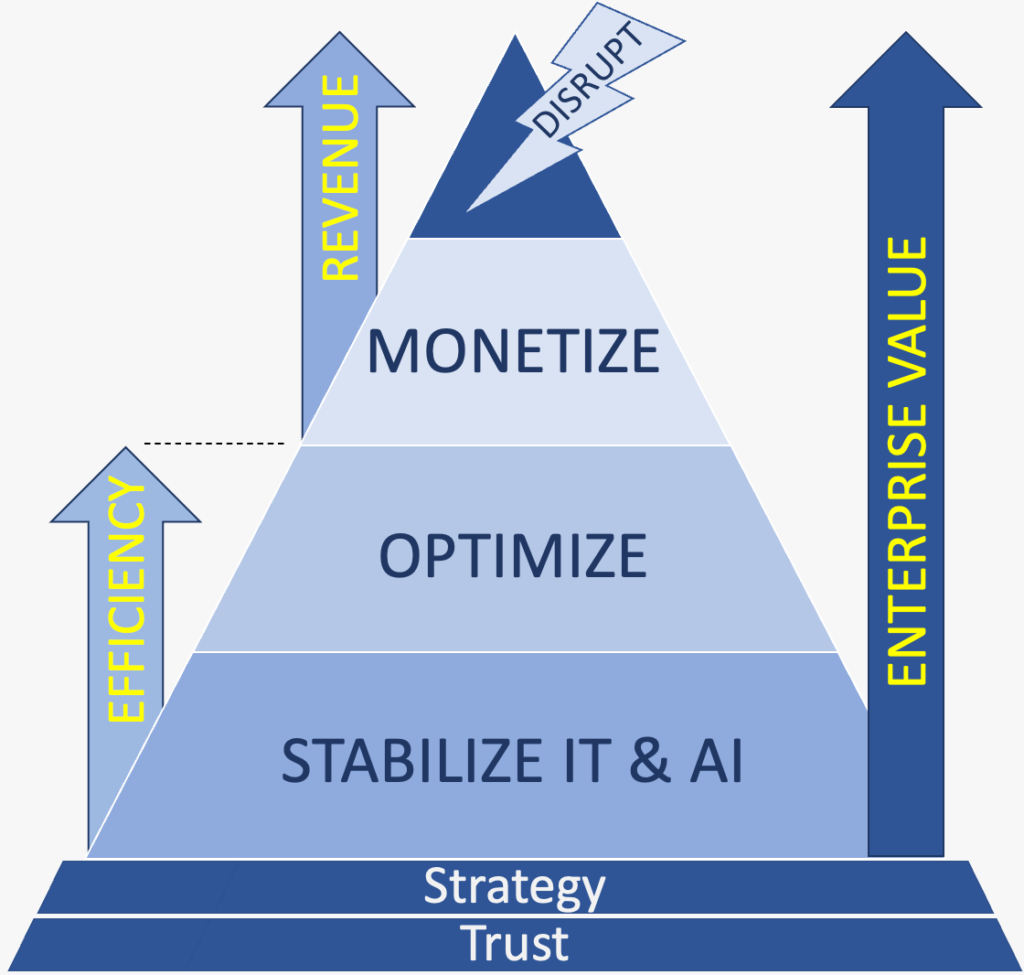
Innovation Vista’s annual benchmark estimates the share of mid-market companies ($10M–$1B in revenue) across 18 industries that have reached Stabilized, Optimized, and Monetized maturity across

The Rack of Reinvented Wheels Running Your Company
Imagine walking into your server room and finding a rack of forty mismatched units, each built by a different employee, each running a critical workflow,

Your Employees Are Already Using AI. You Just Don’t Have a Strategy For It Yet.
by Kevin Ziegler, Fractional CTO and strategic technology advisor Why the next phase of AI leadership in mid-market companies isn’t about adoption. It’s about visibility.
